import re deffind(): text = open('equality.txt','r') l = '' for line in text: if re.findall('[^A-Z][A-Z]{3}([a-z])[A-Z]{3}[^A-Z]',line)!= []: l += re.findall('[^A-Z][A-Z]{3}([a-z])[A-Z]{3}[^A-Z]',line)[0] return l print find()
r = urllib.urlopen("http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=这个值自己换") whileTrue: s = r.fp.read() l = re.findall(r"[0-9]+",s) if l == []: break r = urllib.urlopen("http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing="+l[0]) print l[0]
中间间断一次,显示Yes. Divide by two and keep going. 修改程序继续,程序会被误导到82683,回到上一个是82682 显示There maybe misleading numbers in the text. One example is 82683. Look only for the next nothing and the next nothing is 63579 修改程序继续,最终得到peak.html
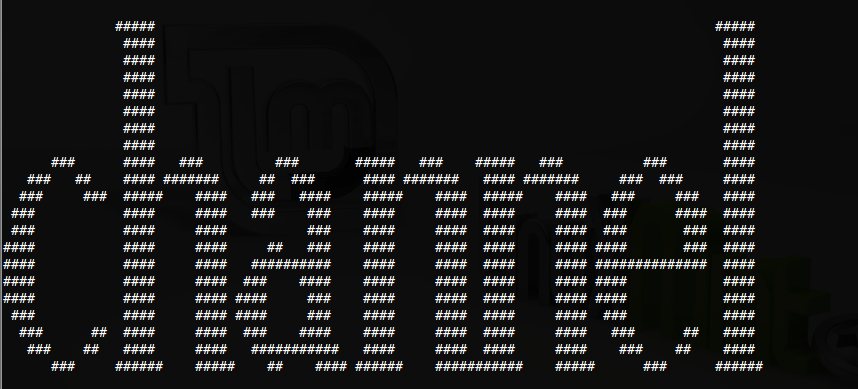
url = 'http://www.pythonchallenge.com/pc/def/banner.p' rst = urllib.urlopen(url).read() pList = pickle.loads(rst) for item in pList: print''.join([i[0] * i[1] for i in item])
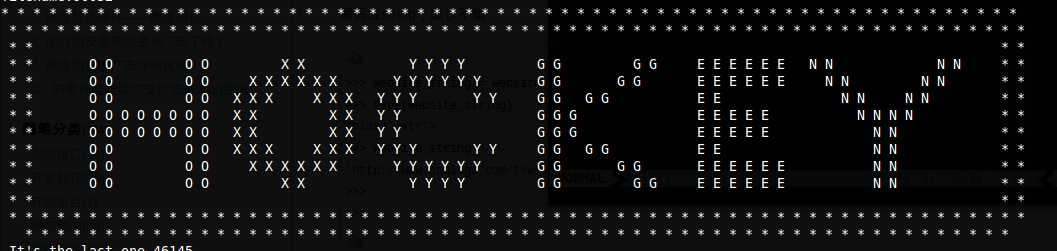
import re import zipfile z = zipfile.ZipFile("../channel.zip") name = input("filename:") whileTrue: withopen('{0}.txt'.format(name),'r') as f: line = f.readlines() iflen(line) > 1: print('Different file {0}'.format(name)) else: try: # print(z.getinfo("{0}.txt".format(name)).comment.decode(),end=' ') p = re.compile('[\d]+').findall(line[0]) assertlen(p) == 1 name = p[0] except: print("It's the last one,{0}".format(name)) print(line) break
上了第五关的当,我加了检查误导的代码,结果发现没有误导的指向 得到末尾文件是46145.txt 内容是Collect the comments. 到这里我不懂了,作了下弊,得知zipfile模块有comment的属性 用上面注释的语句输出,得出下图 到 http://www.pythonchallenge.com/pc/def/hockey.html 它说it’s in the air. look at the letters. 是氧气oxygen。。。。。呵呵哒